
티스토리 뷰
Naive Bayes는 분류(classification) 작업에 특히 적합한 확률론적 머신 러닝 classfier로, 스팸 이메일 탐지, 감성 분석, 텍스트 분류와 같은 NLP (Natural Language Processing, 자연어 처리) 작업에 자주 적용된다.
Naive Bayes의 기본 아이디어는 event와 관련이 있을 수 있는 조건에 대한 사전 지식을 바탕으로 event의 확률을 설명하는 Bayes' theorem (베이즈 정리)에 뿌리를 두고 있다. NLP에서 'event'는 종종 텍스트의 범주 또는 클래스 (class) (예를 들어, '스팸' 또는 '스팸 아님')을 의미하며, '조건 (condition)'은 텍스트에 특정 단어가 있는지 또는 없는지를 의미한다.
Bayes' theorem은 수학적으로 아래와 같이 표현한다.
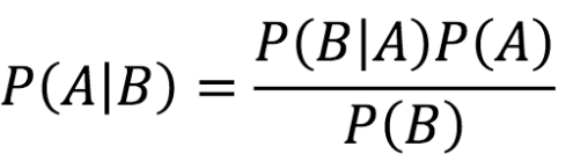
- P(A|B): 데이터 B가 주어졌을 때 가설 A가 성립할 확률 (사후 확률, posterior probability)
- P(B|A): 가설 A가 주어졌을 때 데이터 B의 확률 (likelihood)
- P(A): 가설 A의 확률 (사전 확률, prior probability)
- P(B): 데이터 B의 확률 (증거, evidence)
NLP에 Naive Bayes를 적용할 때 주의해야 할 몇 가지 핵심 사항은 아래와 같다.
- Bag of Words (BoW)
: 텍스트 데이터는 단어의 순서는 중요하지 않지만 단어의 빈도는 중요한 BoW을 사용해 표현되는 경우가 많다. - Naive assumption (순진한 가정)
: classifier는 텍스트의 클래스/카테고리가 주어졌을 때 텍스트의 각 단어가 모든 단어와 조건부로 독립적이라 가정한다. 자연어의 단어에는 종종 종속석이 있기 때문에 (예를 들어, "비"는 종종 "우산"과 함께 사용) 이것은 "Naive" 가정이지만, 놀랍게도 이러한 가정에도 불구하고 Naive Bayes는 많은 NLP 작업에서 꽤 잘 수행된다. - Training (훈련)
: Training 중에 classifier는 training data를 기반으로 카테고리가 주어진 단어의 확률(가능성, likelihood)과 각 카테고리의 확률(prior, 선험치)를 추정한다. - Prediction (예측)
: 새로운 텍스트의 카테고리를 예측하기 위해 classifier는 텍스트가 주어진 각 카테고리의 사후 확률 (posterior probability)를 계산해 가장 높은 확률을 가진 카테고리를 선택한다. - Smoothing (스무딩, 평활하)
: test set의 일부 단어가 training set에 없을 수 있이므로, 확률이 0인 경우를 다루기 위해 Smoothing 기법 (Laplace 나 Add-1 smoothing 같은) 을 적용한다. - 장점
: Naive Bayes는 간단하고 빠르며, 특히 data set가 방대하지 않은 경우 NLP classification 작업에 상당히 좋은 결과를 제공하는 경우가 많다. - 한계점
: 조건부 독립성이라는 가정은 실제 텍스트 데이터에서는 종종 위반된다. 또한 추가 기능이나 방법론이 통합되지 않는 한 문맥이나 어순을 이해하는 능력이 부족하다.
결론적으로, Naive Bayes는 특정 카테고리에 주어진 단어의 확률을 기반으로 텍스트 분류를 위해 NLP에 널리 사용되는 간단한 classfier다.
참고
- https://medium.com/@the_nimala/bayes-theorem-basic-in-machine-learning-3f58066019ab
반응형
'기술(Tech, IT) > 머신 러닝(Machine Learning)' 카테고리의 다른 글
| [ML] Multinomial Naive Bayes (다항 분포 나이브 베이즈) - 2 (0) | 2023.10.31 |
|---|---|
| [ML] Vecotrizer (벡터화 기법) (0) | 2023.10.30 |
| [ML] TF-IDF - 2 (0) | 2023.10.28 |
| [ML] Viterbi Algorithm (비터비 알고리즘) (2) | 2023.10.23 |
| [ML] Hidden Markov Model (HMM, 은닉 마르코프 모델) - 1 (0) | 2023.10.22 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- The Economist
- 오블완
- 이코노미스트 에스프레소
- Android
- DICTIONARY
- socket programming
- min heap
- 안드로이드
- leetcode
- 머신 러닝
- Hash Map
- ml
- tf-idf
- I2C
- 리트코드
- java
- 티스토리챌린지
- vertex shader
- Computer Graphics
- 투 포인터
- Python
- join
- machine learning
- defaultdict
- 소켓 프로그래밍
- The Economist Espresso
- 파이썬
- C++
- 딕셔너리
- 이코노미스트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
글 보관함
반응형